初步性能测试
2012-06-13 23:00:00
因为接下去要做优化工作,在此之前,先做下简单的性能测试。
比较的对象是std::regex,暂时只比较两项:
- 解析正则表达式的速度
- 使用解析好的正则表达式去匹配字符串的速度。
测试代码如下:
1SECTION_BEGIN(StdRegExParse100000);
2PERFORMANCE_TEST_BEGIN(StdRegExParse100000);
3for (int i = 0; i < 100000; ++i)
4{
5 wregex r;
6 r.assign(L"http://([a-zA-Z0-9\\-]+.)+[a-zA-Z]+/");
7}
8PERFORMANCE_TEST_END(StdRegExParse100000);
9SECTION_END();
10
11SECTION_BEGIN(xlRegExpParse100000);
12PERFORMANCE_TEST_BEGIN(xlRegExpParse100000);
13for (int i = 0; i < 100000; ++i)
14{
15 RegExp r;
16 r.Parse(L"http://([a-zA-Z0-9\\-]+.)+[a-zA-Z]+/");
17}
18PERFORMANCE_TEST_END(xlRegExpParse100000);
19SECTION_END();
20
21SECTION_BEGIN(StdRegExMatch100000);
22{
23 wregex r;
24 r.assign(L"http://([a-zA-Z0-9\\-]+.)+[a-zA-Z]+/");
25 PERFORMANCE_TEST_BEGIN(StdRegExMatch100000);
26 for (int i = 0; i < 100000; ++i)
27 {
28 regex_match(L"http://w-1.w-2.w-3.streamlet.org/", r);
29 }
30 PERFORMANCE_TEST_END(StdRegExMatch100000);
31}
32SECTION_END();
33
34SECTION_BEGIN(xlRegExpMatch100000);
35{
36 RegExp r;
37 r.Parse(L"http://([a-zA-Z0-9\\-]+.)+[a-zA-Z]+/");
38 PERFORMANCE_TEST_BEGIN(xlRegExpMatch100000);
39 for (int i = 0; i < 100000; ++i)
40 {
41 r.Match(L"http://w-1.w-2.w-3.streamlet.org/");
42 }
43 PERFORMANCE_TEST_END(xlRegExpMatch100000);
44}
45SECTION_END();
前两则是分别使用std::wregex和xl::RegExp解析"http://([a-zA-Z0-9\-]+.)+[a-zA-Z]+/"十万次,后两则是拿来匹配http://w-1.w-2.w-3.streamlet.org/十万次。 结果如下:
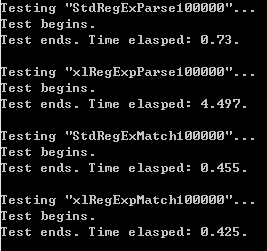
匹配速度差很多,解析速度差不多。 考虑到在解析“?”“+”“*”的时候,引入了很多ε边,于是对那部分做点优化,去除不必要的ε边和节点构造,然后再测试:
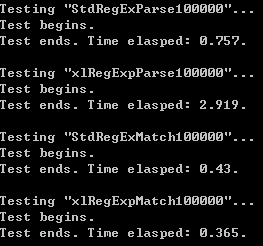
可以看到有所提高,但是解析速度还是跟std:wregex的差很多,匹配速度有明显领先。目前只解析到ε边、-NFA,如果再做状态机转化,虽然会提高匹配速度,可是解析速度会进一步下降。因此,一开始就要考虑使用一种更高效的状态机存储方法。
这两天着凉生病了,好难受啊……
首发:http://www.cppblog.com/Streamlet/archive/2012/06/13/178704.html