解析正则表达式(一)概要
2012-06-03 15:16:00
引言
想搞正则表达式解析器好久了。前面由于一些基础设施没准备好,没法开始动手。现在 xlLib 里头准备的差不多了,可以着手实施了。
在做这件事之前,读了好几遍 @vczh 的文章《构造可配置词法分析器》《构造正则表达式引擎》(http://www.cppblog.com/vczh/archive/2008/05/22/50763.html),给了很大的帮助和启发,在这里表示感谢。(虽然到现在为止还没有完全读懂。)
编译原理理论上的东西我了解的还不是很多。正则表达式在文本解析中有着特殊的作用,特殊之一是,它的每个词法单元都是单个字符(转义的除外),因此词法分析阶段需要做的工作仅仅是转义、识别单个字符。
本文我们实现以下功能:
- 词法分析
- 语法分析
- 操作符“|”的支持
- 小括号“()”的支持(仅用于改变优先级)
词法分析
我们定义一个 Token 结构来描述一个词法单元:
1enum TokenType
2{
3 TT_Eof,
4 TT_VerticalBar, // |
5 TT_OpenParen, // (
6 TT_CloseParen, // )
7 TT_OrdinaryChar
8};
9
10struct Token
11{
12 TokenType type;
13 Char ch;
14 size_t length;
15
16 Token(TokenType type = TT_OrdinaryChar, Char ch = 0, size_t length = 1)
17 : ch(ch), type(type), length(length)
18 {
19
20 }
21};
其中 TokenType 表示哪种类型,除了普通字符外,我们支持的单词类型有竖线、左小括号、右小括号,EOF 严格的说并不属于单词,但这里我们需要一种表示单词读尽的方法。ch 表示这个 Token 的字符,length 表示这个 Token 的字符个数,一般来说是 1,如果碰到转义的,那就不是 1。之所以要记录长度,是因为有时候试探性地多读了一个 Token 后,需要回退回去。
整个词法分析就由下面这一个函数去做:
1Token LookAhead()
2{
3 if (m_nCurrentPosition >= m_strRegExp.Length())
4 {
5 return Token(TT_Eof, 0, 0);
6 }
7
8 Char ch = m_strRegExp[m_nCurrentPosition++];
9 TokenType type = TT_OrdinaryChar;
10
11 if (ch == L'\\')
12 {
13 if (m_nCurrentPosition < m_strRegExp.Length())
14 {
15 return Token(TT_OrdinaryChar, m_strRegExp[m_nCurrentPosition++], 2);
16 }
17 }
18
19 switch (ch)
20 {
21 case L'|':
22 type = TT_VerticalBar;
23 break;
24 case L'(':
25 type = TT_OpenParen;
26 break;
27 case L')':
28 type = TT_CloseParen;
29 break;
30 default:
31 break;
32 }
33
34 return Token(type, ch);
35}
其中 m_strRegExp 是要解析的表达式,m_nCurrentPosition 是当前位置。
我们的转义定义是,从前往后读,反斜杠 \ 后面的一个字符,转义为该字符本身。反斜杠后面跟任何字符,都是合法的。如果反斜杠出现在最后一个位置,那么容错处理,视为反斜杠这个字符。其余未经转义的,除了我们已定义功能的“|”“(”“)”外,都作为普通字符处理。目前这样的转义处理,不支持 \d、\uXXXX 之类的写法,这些以后再考虑。
顺便再写一个回退用的函数:
1void Backward(const Token &token)
2{
3 m_nCurrentPosition -= token.length;
4}
语法分析
文法介绍
按照本文开头定义的,我们的“正则表达式”的语法可以用以下的 EBNF 文法描述:
Expr -> ExprNoOr { "|" ExprNoOr }
ExprNoOr -> ExprNoGroup { "(" Expr ")" ExprNoGroup }
ExprNoGroup -> { OrdinaryChar }
(大概这个意思,不知道写得规不规范) “|”的优先级最低,整个表达式(Expr)首先被第一级竖线分割成各个版本不带竖线的子式(ExprNoOr)。 每个 ExprNoOr,被括号分分隔,括号外面的是不带括号(当然也不带竖线)的子式(ExprNoGroup),括号的里面,视为一个完整的表达式(Expr)。整个 ExprNoOr,由若干个 ExprNoGroup 或者带括号的表达式连接构成。注意这里有个递归定义。到目前为止,所有的子式将终结于 ExprNoGroup。 ExprNoGroup 定义为由若干个普通字符(不含“|”“(”“)”)组成的字符串。
状态机
这个,完整的叫做“非确定有限状态机”(NFA),理论上的东西我目前不是很精确地了解,以后总结。现在把代码实现中所需要的预备知识和算法讲一下。 举个例子,对于符合我们前面定义的正则表达式“abc”,我们可以用一下的 NFA 表示:

匹配字符串的时候,我们从起始状态 S 开始,依次用每个字符区尝试匹配每一条边,如果最后走到结束状态 E,说明匹配成功。
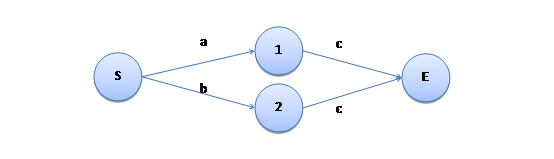
再例如“(a|b)c”,它的 NFA 表示如下:
又例如“a|ab”,它的 NFA 表示如下:
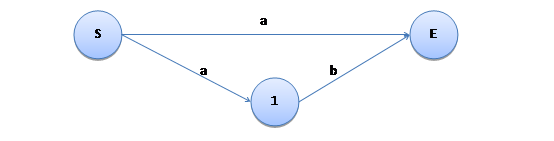
这时,一个状态后面可能有不止一条边满足某个字符的通过条件,匹配的时候可能需要进行回溯操作。
另外,由于一下代码实现实现上的原因,“a|bc”可能被弄成下面这个样子:

跟刚才的相比,多了一条“ε边”。ε边是一条可以不消耗字符直接通过的边。具有ε边的 NFA 叫做 ε-NFA。
好了,上面介绍了我们在本文定义的正则表达式语法中可能涉及到的状态机的样子。操作符“|”会导致状态机产生支路;括号改变优先级,体现在支路的位置不同。
我们使用一个图结构(xl::Graph)表示状态机,图的简单实现见: http://xllib.codeplex.com/SourceControl/changeset/view/16803#160588
节点的数据结构定义如下:
1struct Node
2{
3public:
4 Node() : m_nIdentify(++ms_nCounter)
5 {
6
7 }
8
9 int m_nIdentify;
10
11 static int ms_nCounter;
12};
13
14__declspec(selectany) int Node::ms_nCounter = 0;
没有特别的数据,只带一个类实例计数,以区分不同的实例。
边的数据结构定义如下:
1struct Edge
2{
3 Edge()
4 : m_bEpsilon(true), m_chBegin(0), m_chEnd(0)
5 {
6
7 }
8
9 Edge(Char ch)
10 : m_bEpsilon(false), m_chBegin(ch), m_chEnd(ch)
11 {
12
13 }
14
15 Edge(Char chBegin, Char chEnd)
16 : m_bEpsilon(false), m_chBegin(chBegin), m_chEnd(chEnd)
17 {
18
19 }
20
21 bool Match(Char ch)
22 {
23 if (m_bEpsilon)
24 {
25 return false;
26 }
27
28 return (ch >= m_chBegin && ch <= m_chEnd);
29 }
30
31 bool bEpsilon;
32 Char chBegin;
33 Char chEnd;
34};
代码实现
我们将用一个类 xl::RegExp 来实现这个简单的“正则表达式”。一些成员变量定义如下:
1typedef Graph<Node, Edge> StateMachine;
2typedef SharedPtr<StateMachine> StateMachinePtr;
3
4StateMachinePtr m_spStateMachine;
5StateMachine::NodePtr m_pBegin;
6StateMachine::NodePtr m_pEnd;
7
8String m_strRegExp;
9int m_nCurrentPosition;
m_spStateMachine 就是状态机,m_pBegin 和 m_pEnd 是头指针和尾指针。m_strRegExp 保存待解析的表达式,m_nCurrentPosition 是 LookAhead 里面保存当前位置的。
入口函数:
1bool Parse(const String &s)
2{
3 m_strRegExp = s;
4 m_nCurrentPosition = 0;
5 m_spStateMachine = new StateMachine;
6 m_pBegin = m_spStateMachine->AddNode(NewNode());
7 m_pEnd = Parse(m_pBegin);
8
9 if (m_pEnd == nullptr)
10 {
11 return false;
12 }
13
14 return true;
15}
简单做下初始化和准备工作,将控制权交给另一个 Parse 函数,最后检查结果。
有几个为了书写方便而引入的状态机操作函数这里先提一下:
1// 创建一个节点(不加入状态机)
2StateMachine::NodePtr NewNode()
3{
4 return new StateMachine::NodeType();
5}
6
7// 创建一条ε边(不加入状态机)
8StateMachine::EdgePtr NewEdge()
9{
10 return new StateMachine::EdgeType();
11}
12
13// 创建一条可通过一个字符的边(不加入状态机)
14StateMachine::EdgePtr NewEdge(Char ch)
15{
16 return new StateMachine::EdgeType(Edge(ch));
17}
18
19// 创建一条可通过一个区间的字符的边(不加入状态机)
20StateMachine::EdgePtr NewEdge(Char chBegin, Char chEnd)
21{
22 return new StateMachine::EdgeType(Edge(chBegin, chEnd));
23}
24
25// 从一个指定节点连一条可通过一个字符的边到新节点,返回新节点
26StateMachine::NodePtr AddNormalNode(StateMachine::NodePtr pNodeFrom, Char chEdgeChar)
27{
28 StateMachine::EdgePtr pEdge = NewEdge(chEdgeChar);
29 StateMachine::NodePtr pNode = NewNode();
30
31 m_spStateMachine->AddNode(pNode);
32 m_spStateMachine->AddEdge(pEdge, pNodeFrom, pNode);
33
34 return pNode;
35}
下面是依据 EBNF 而构造的一组语法分析函数,每个函数大体长成这样:
1StateMachine::NodePtr ParseXXX(StateMachine::NodePtr pNode);
传入的是当前节点,返回的是解析完毕后的当前节点。如果出现错误,那么返回 nullptr。
重新回顾一下 EBNF:
Expr -> ExprNoOr { "|" ExprNoOr }
ExprNoOr -> ExprNoGroup { "(" Expr ")" ExprNoGroup }
ExprNoGroup -> { OrdinaryChar }
函数如下:
1StateMachine::NodePtr Parse(StateMachine::NodePtr pNode)
2{
3 StateMachine::NodePtr pCurrent = ParseExpr(pNode);
4
5 Token token = LookAhead();
6
7 if (token.type != TT_Eof)
8 {
9 return nullptr;
10 }
11
12 return pCurrent;
13}
这个 Parse 并不属于 EBNF 的一部分,它也是入口性质的,为了调用 ParseExpr。因为 ParseExpr 需要处理的可能是整个表达式,也可能是括号里的子式,所以 ParseExpr 不能以 TT_Eof 作为结束,而是以不认识的字符作为结束。上面的 Parse 是针对整个表达式的,它来检验表达式是否全部解析完毕。
下面是 ParseExpr:
1StateMachine::NodePtr ParseExpr(StateMachine::NodePtr pNode)
2{
3 StateMachine::NodePtr pCurrent = ParseExprNoOr(pNode);
4
5 if (pCurrent == nullptr)
6 {
7 return nullptr;
8 }
9
10 while (true)
11 {
12 Token token = LookAhead();
13
14 if (token.type != TT_VerticalBar)
15 {
16 Backward(token);
17 return pCurrent;
18 }
19
20 StateMachine::NodePtr pNewNode = ParseExprNoOr(pNode);
21 StateMachine::EdgePtr pEdge = NewEdge();
22 m_spStateMachine->AddEdge(pEdge, pNewNode, pCurrent);
23 }
24
25 return nullptr;
26}
按照文法中描述的,它首先做一遍 ParseExprNoOr,然后检查下一个字符是不是“|”,如果是,继续 ParseExprNoOr,如此循环往复。直到某一次 ParseExprNoOr 之后读到的不是“|”。
注意到此处有个并联处理。在“|”之前已经有了一个由第一次 ParseExprNoOr 产生的新节点 pCurrent,第二次(以及第三次、第四次……) ParseExprNoOr 产生的新节点 pNewNode,都用一条ε边连接到 pCurrent。
接下来是 ParseExprNoOr:
1StateMachine::NodePtr ParseExprNoOr(StateMachine::NodePtr pNode)
2{
3 StateMachine::NodePtr pCurrent = pNode;
4
5 while (true)
6 {
7 pCurrent = ParseExprNoGroup(pCurrent);
8
9 if (pCurrent == nullptr)
10 {
11 return nullptr;
12 }
13
14 Token token = LookAhead();
15
16 if (token.type != TT_OpenParen)
17 {
18 Backward(token);
19 return pCurrent;
20 }
21
22 pCurrent = ParseExpr(pCurrent);
23
24 if (pCurrent == nullptr)
25 {
26 return nullptr;
27 }
28
29 token = LookAhead();
30
31 if (token.type != TT_CloseParen)
32 {
33 return nullptr;
34 }
35 }
36
37 return nullptr;
38}
它跟文法中写的形式上稍稍有点不一样。文法中是“ExprNoGroup { "(" Expr ")" ExprNoGroup }”,而现在好像是“{ ExprNoGroup "(" Expr ")" }”。其实是一样的,循环的退出点是某一次 ParseExprNoGroup 之后读到的不是“(”,要不要重复取决于“(”有没有出现。
以下是 ParseExprNoGroup,也是本文的解析终点:
1StateMachine::NodePtr ParseExprNoGroup(StateMachine::NodePtr pNode)
2{
3 StateMachine::NodePtr pCurrent = pNode;
4
5 while (true)
6 {
7 Token token = LookAhead();
8
9 if (token.type != TT_OrdinaryChar)
10 {
11 Backward(token);
12 return pCurrent;
13 }
14
15 pCurrent = AddNormalNode(pCurrent, token.ch);
16
17 if (pCurrent == nullptr)
18 {
19 return nullptr;
20 }
21 }
22
23 return nullptr;
24}
它只认普通字符,有的话把它加入状态机。
至此,我们的语法分析已经做完了,最终得到一个ε-NFA。之后我们使用这个ε-NFA来匹配字符串。
匹配检验
相对于语法分析,匹配就比较简单了。我们现在要做的工作是:已知一个正则表达式对应的ε-NFA,给出一个字符串,判定该字符串是否符合正则表达式的描述。
由于我们现在直接使用ε-NFA,所以可能需要回溯,因此,简单起见写成如下递归形式:
1
2bool Match(const String &s)
3{
4 return Match(s, 0, m_pBegin);
5}
6
7bool Match(const String &s, int i, StateMachine::NodePtr pNode)
8{
9 if (pNode == m_pEnd)
10 {
11 if (i < s.Length())
12 {
13 return false;
14 }
15
16 return true;
17 }
18
19 for (auto it = pNode->arrNext.Begin(); it != pNode->arrNext.End(); ++it)
20 {
21 if (Match(s, i, *it))
22 {
23 return true;
24 }
25 }
26
27 return false;
28}
29
30bool Match(const String &s, int i, StateMachine::EdgePtr pEdge)
31{
32 if (!pEdge->tValue.bEpsilon)
33 {
34 if (i >= s.Length())
35 {
36 return false;
37 }
38
39 if (!pEdge->tValue.Match(s[i]))
40 {
41 return false;
42 }
43
44 return Match(s, i + 1, pEdge->pNext);
45 }
46 else
47 {
48 return Match(s, i, pEdge->pNext);
49 }
50}
51
第一个 Match 是入口。第二个 Match 是针对某个节点,它遍历该节点的所有后续的边,如果从某一条边解析后续字符串成功,就结束,否则继续尝试下一条边。第三个 Match 是针对某条边的,如果能通过这条边,就继续到下个节点。这里有个对ε边的特殊处理,如果是ε边,i 没有加一,直接到下个节点。
上述过程是一个深度优先的搜索过程,如果能走到最后的节点,且字符串也刚刚走到最后,算匹配成功。
单元测试
先做一些常规的测试:
1XL_TEST_CASE()
2{
3 RegExp r;
4 XL_TEST_ASSERT(r.Parse(L""));
5 XL_TEST_ASSERT(r.Parse(L"||"));
6 XL_TEST_ASSERT(r.Parse(L"()"));
7 XL_TEST_ASSERT(r.Parse(L"|"));
8 XL_TEST_ASSERT(r.Parse(L"(|)"));
9 XL_TEST_ASSERT(r.Parse(L"(||)"));
10 XL_TEST_ASSERT(r.Parse(L"()|()"));
11 XL_TEST_ASSERT(!r.Parse(L"("));
12 XL_TEST_ASSERT(!r.Parse(L")"));
13}
14
15XL_TEST_CASE()
16{
17 RegExp r;
18
19 XL_TEST_ASSERT(r.Parse(L""));
20 XL_TEST_ASSERT(r.Match(L""));
21 XL_TEST_ASSERT(!r.Match(L"a"));
22
23 XL_TEST_ASSERT(r.Parse(L"a"));
24 XL_TEST_ASSERT(r.Match(L"a"));
25 XL_TEST_ASSERT(!r.Match(L"ab"));
26 XL_TEST_ASSERT(!r.Match(L"b"));
27
28 XL_TEST_ASSERT(r.Parse(L"(a)"));
29 XL_TEST_ASSERT(r.Match(L"a"));
30 XL_TEST_ASSERT(!r.Match(L"ab"));
31 XL_TEST_ASSERT(!r.Match(L"b"));
32
33 XL_TEST_ASSERT(r.Parse(L"ab|c"));
34 XL_TEST_ASSERT(!r.Match(L"a"));
35 XL_TEST_ASSERT(!r.Match(L"b"));
36 XL_TEST_ASSERT(r.Match(L"c"));
37 XL_TEST_ASSERT(r.Match(L"ab"));
38 XL_TEST_ASSERT(!r.Match(L"bc"));
39 XL_TEST_ASSERT(!r.Match(L"ac"));
40
41 XL_TEST_ASSERT(r.Parse(L"a(b|c)"));
42 XL_TEST_ASSERT(!r.Match(L"a"));
43 XL_TEST_ASSERT(!r.Match(L"b"));
44 XL_TEST_ASSERT(!r.Match(L"c"));
45 XL_TEST_ASSERT(r.Match(L"ab"));
46 XL_TEST_ASSERT(r.Match(L"ac"));
47 XL_TEST_ASSERT(!r.Match(L"bc"));
48}
49
50XL_TEST_CASE()
51{
52 RegExp r;
53
54 XL_TEST_ASSERT(r.Parse(L"\\|"));
55 XL_TEST_ASSERT(r.Match(L"|"));
56
57 XL_TEST_ASSERT(r.Parse(L"\\("));
58 XL_TEST_ASSERT(r.Match(L"("));
59
60 XL_TEST_ASSERT(r.Parse(L"\\)"));
61 XL_TEST_ASSERT(r.Match(L")"));
62
63 XL_TEST_ASSERT(r.Parse(L"\\\\"));
64 XL_TEST_ASSERT(r.Match(L"\\"));
65
66 XL_TEST_ASSERT(r.Parse(L"\\"));
67 XL_TEST_ASSERT(r.Match(L"\\"));
68
69 XL_TEST_ASSERT(r.Parse(L"\\|(\\(|\\))"));
70 XL_TEST_ASSERT(r.Match(L"|("));
71 XL_TEST_ASSERT(r.Match(L"|)"));
72}
嗯……没有成就感。再来点有意思的。我们目前虽然只支持“|”和“(”“)”,但能做的事情已经很多了,比如匹配 0 到 255 的数字。
我们将 0 到 255 的数分为五类:
- 一位数:(0|1|2|3|4|5|6|7|8|9)
- 两位数:(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)
- 三位数:
- 0到199:(0|1)(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)
- 200到249:2(0|1|2|3|4)(0|1|2|3|4|5|6|7|8|9)
- 250到255:25(0|1|2|3|4|5)
将这五个使用“|”连起来,就是一个0到255的正则表达式。
1XL_TEST_CASE()
2{
3 RegExp r;
4
5 XL_TEST_ASSERT(r.Parse(L"(0|1|2|3|4|5|6|7|8|9)|"
6 L"(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)|"
7 L"(0|1)(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)|"
8 L"2(0|1|2|3|4)(0|1|2|3|4|5|6|7|8|9)|"
9 L"25(0|1|2|3|4|5)"));
10 XL_TEST_ASSERT(r.Match(L"0"));
11 XL_TEST_ASSERT(r.Match(L"1"));
12 XL_TEST_ASSERT(r.Match(L"2"));
13 XL_TEST_ASSERT(r.Match(L"3"));
14 XL_TEST_ASSERT(r.Match(L"4"));
15 XL_TEST_ASSERT(r.Match(L"5"));
16 XL_TEST_ASSERT(r.Match(L"6"));
17 XL_TEST_ASSERT(r.Match(L"7"));
18 XL_TEST_ASSERT(r.Match(L"8"));
19 XL_TEST_ASSERT(r.Match(L"9"));
20 XL_TEST_ASSERT(r.Match(L"10"));
21 XL_TEST_ASSERT(r.Match(L"20"));
22 XL_TEST_ASSERT(r.Match(L"30"));
23 XL_TEST_ASSERT(r.Match(L"40"));
24 XL_TEST_ASSERT(r.Match(L"50"));
25 XL_TEST_ASSERT(r.Match(L"60"));
26 XL_TEST_ASSERT(r.Match(L"70"));
27 XL_TEST_ASSERT(r.Match(L"80"));
28 XL_TEST_ASSERT(r.Match(L"90"));
29 XL_TEST_ASSERT(r.Match(L"100"));
30 XL_TEST_ASSERT(r.Match(L"199"));
31 XL_TEST_ASSERT(r.Match(L"200"));
32 XL_TEST_ASSERT(r.Match(L"249"));
33 XL_TEST_ASSERT(r.Match(L"250"));
34 XL_TEST_ASSERT(r.Match(L"251"));
35 XL_TEST_ASSERT(r.Match(L"252"));
36 XL_TEST_ASSERT(r.Match(L"253"));
37 XL_TEST_ASSERT(r.Match(L"254"));
38 XL_TEST_ASSERT(r.Match(L"255"));
39 XL_TEST_ASSERT(!r.Match(L"256"));
40 XL_TEST_ASSERT(!r.Match(L"260"));
41 XL_TEST_ASSERT(!r.Match(L"300"));
42}
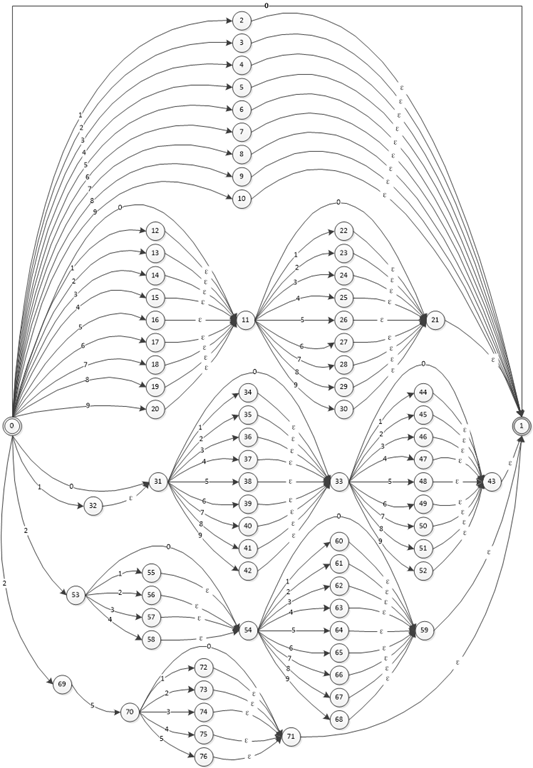
我们可以 YY 下现在的状态机的样子:
再来一个例子,匹配 IPv4。我们刚才已经有了0到255的数字的表示方法了,将他们用句点“.”连接起来就可以了。注意,“.”在我们目前的定义中没有特殊含义,只是普通字符,所以不必转义(当然转义一下也没问题)。
1XL_TEST_CASE()
2{
3 RegExp r;
4
5 // IPv4 address
6 XL_TEST_ASSERT(r.Parse(L"("
7 L"(0|1|2|3|4|5|6|7|8|9)|"
8 L"(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)|"
9 L"(0|1)(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)|"
10 L"2(0|1|2|3|4)(0|1|2|3|4|5|6|7|8|9)|"
11 L"25(0|1|2|3|4|5)"
12 L").("
13 L"(0|1|2|3|4|5|6|7|8|9)|"
14 L"(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)|"
15 L"(0|1)(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)|"
16 L"2(0|1|2|3|4)(0|1|2|3|4|5|6|7|8|9)|"
17 L"25(0|1|2|3|4|5)"
18 L").("
19 L"(0|1|2|3|4|5|6|7|8|9)|"
20 L"(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)|"
21 L"(0|1)(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)|"
22 L"2(0|1|2|3|4)(0|1|2|3|4|5|6|7|8|9)|"
23 L"25(0|1|2|3|4|5)"
24 L").("
25 L"(0|1|2|3|4|5|6|7|8|9)|"
26 L"(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)|"
27 L"(0|1)(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)|"
28 L"2(0|1|2|3|4)(0|1|2|3|4|5|6|7|8|9)|"
29 L"25(0|1|2|3|4|5)"
30 L")"));
31 XL_TEST_ASSERT(r.Match(L"192.168.1.1"));
32 XL_TEST_ASSERT(r.Match(L"0.0.0.0"));
33 XL_TEST_ASSERT(r.Match(L"255.255.255.255"));
34 XL_TEST_ASSERT(!r.Match(L"0.0.0.256"));
35}
小结
本文构造了正则表达式解析器的一个基本框架,并且完成了对“|”“(”“)”这三个操作符的语法分析。在这里,我们确定了基本的数据结构和算法,以后将在此基础上扩展,实现更多的功能。
本文中定义的节点结构和边结构,只适用于目前的需求,以后如果满足不了需要,将会修改。本文所使用的 xl::Graph 功能也并不完善,以后也会同步修改。本文使用ε-NFA直接进行匹配检验,检验的时候使用了较多的递归,性能上并没有达到比较优化的状态,这将在未来某篇中讨论。在最初的几篇中,我们将着重于实现一些必要的功能。
本文中涉及的实现代码在: http://xllib.codeplex.com/SourceControl/changeset/view/16815#270275 单元测试代码在: http://xllib.codeplex.com/SourceControl/changeset/view/16815#270901
欢迎探讨、批评、指正。
首发:http://www.cppblog.com/Streamlet/archive/2012/06/03/177330.html