引言
根据预告,这篇我们对“?”“+”“”进行处理,实现对重复的支持。“x?”匹配0个或1个“x”,“x+”匹配1到任意个“x”,“x”匹配0到任意个“x”。
有了重复,就有贪婪模式和非贪婪模式。在贪婪模式下,“x+”匹配“xxxyyy”中的“xxx”;在非贪婪模式下,“x+”匹配“xxxyyy”中的第一个“x”。为了区别两种模式,按照通常的语法,我们在重复控制符号后面加一个“?”表示非贪婪模式,不加默认贪婪模式。现在,有效的语法有“x?”“x??”“x+”“x+?”“x*”“x*?”。
那么,“x”可以是什么呢?重复符号的优先级挺高的,到目前为止,“x”可以是单个字符,也可以是中括号表达是,也可以是小括号括起来的表达式。
下面,我们进行语法分析。
语法分析
文法介绍
还是回顾一下上次的文法:
Expr -> ExprNoOr { "|" ExprNoOr }
ExprNoOr -> ExprNoGroup { "(" Expr ")" ExprNoGroup }
ExprNoGroup -> ExprNoCollection { "[" ExprCollection "]" ExprNoCollection }
ExprCollection -> [ "^" ] { OrdinaryChar | OrdinaryChar "-" OrdinaryChar }
ExprNoCollection -> { OrdinaryChar }
从上面的结构看,重复符号可以加在 ExprNoCollection 的每一个字符后面,也可以加在 ExprNoGroup 里的中括号表达式后面,也可以加在 ExprNoOr 的小括号表达式后面。不过这样看上去有点乱,我们整理一下,换种写法:
Expr -> SubExpr { "|" SubExpr }
SubExpr -> { Phrase }
Phrase -> Word [ Repeater ]
Repeater -> ( "?" | "+" | "*" ) [ "?" ]
Word -> OrdinaryChar | "[" Collection "]" | "(" Expr ")"
Collection -> [ "^" ] { OrdinaryChar | OrdinaryChar "-" OrdinaryChar }
OrdinaryChar -> All ordinary characters
首先,我们把由“|”分开的各个部分称为SubExpr,SubExpr由很多Phrase构成,每个Phrase由一个Word以及可能存在的Repeater构成,Word分为三种,普通字符、中括号表达式、小括号表达式。
首先,不考虑Repeater部分,即:
Phrase -> Word
我们把现有代码调整一下,使得符合文法表述的结构,然后再添加Repeater部分。
结构调整
调整现有代码不详细解释了,纯贴代码(不含Repeater处理哦):
1StateMachine::NodePtr ParseExpr(StateMachine::NodePtr pNode)
2{
3 StateMachine::NodePtr pCurrent = ParseSubExpr(pNode);
4
5 if (pCurrent == nullptr)
6 {
7 return nullptr;
8 }
9
10 while (true)
11 {
12 Token token = LookAhead();
13
14 if (token.type != TT_VerticalBar)
15 {
16 Backward(token);
17 return pCurrent;
18 }
19
20 StateMachine::NodePtr pNewNode = ParseSubExpr(pNode);
21 StateMachine::EdgePtr pEdge = NewEdge();
22 m_spStateMachine->AddEdge(pEdge, pNewNode, pCurrent);
23 }
24
25 return nullptr;
26}
27
28StateMachine::NodePtr ParseSubExpr(StateMachine::NodePtr pNode)
29{
30 StateMachine::NodePtr pCurrent = pNode;
31
32 while (true)
33 {
34 StateMachine::NodePtr pNewNode = ParsePhrase(pCurrent);
35
36 if (pNewNode == pCurrent || pNewNode == nullptr)
37 {
38 return pNewNode;
39 }
40
41 pCurrent = pNewNode;
42 }
43
44 return nullptr;
45}
46
47StateMachine::NodePtr ParsePhrase(StateMachine::NodePtr pNode)
48{
49 StateMachine::NodePtr pCurrent = ParseWord(pNode);
50
51 if (pCurrent == nullptr)
52 {
53 return nullptr;
54 }
55
56 // TODO: Parse Repeater
57
58 return pCurrent;
59}
60
61StateMachine::NodePtr ParseWord(StateMachine::NodePtr pNode)
62{
63 StateMachine::NodePtr pCurrent = pNode;
64
65 Token token = LookAhead();
66
67 switch (token.type)
68 {
69 case TT_OpenParen:
70 {
71 pCurrent = ParseExpr(pCurrent);
72
73 if (pCurrent == nullptr)
74 {
75 return nullptr;
76 }
77
78 token = LookAhead();
79
80 if (token.type != TT_CloseParen)
81 {
82 return nullptr;
83 }
84 }
85 break;
86 case TT_OpenBracket:
87 {
88 pCurrent = ParseCollection(pCurrent);
89
90 if (pCurrent == nullptr)
91 {
92 return nullptr;
93 }
94
95 token = LookAhead();
96
97 if (token.type != TT_CloseBracket)
98 {
99 return nullptr;
100 }
101 }
102 break;
103 case TT_OrdinaryChar:
104 {
105 pCurrent = AddNormalNode(pCurrent, token.ch);
106
107 if (pCurrent == nullptr)
108 {
109 return nullptr;
110 }
111 }
112 break;
113 default:
114 Backward(token);
115 return pCurrent;
116 }
117
118 return pCurrent;
119}
120
121StateMachine::NodePtr ParseCollection(StateMachine::NodePtr pNode)
122{
123 bool bFirst = true;
124 bool bInHyphen = false;
125 bool bAcceptHyphen = false;
126 Char chLastChar = 0;
127
128 bool bOpposite = false;
129 IntervalSet<Char> is;
130
131 bool bContinue = true;
132
133 while (bContinue)
134 {
135 Token token = LookAhead();
136
137 switch (token.type)
138 {
139 case TT_Caret:
140 {
141 if (!bFirst)
142 {
143 return nullptr;
144 }
145 else
146 {
147 bOpposite = true;
148 }
149 }
150 break;
151 case TT_Hyphen:
152 {
153 if (bInHyphen || !bAcceptHyphen)
154 {
155 return nullptr;
156 }
157 else
158 {
159 bInHyphen = true;
160 }
161 }
162 break;
163 case TT_OrdinaryChar:
164 {
165 if (bInHyphen)
166 {
167 is.Union(Interval<Char>(chLastChar, token.ch));
168 bInHyphen = false;
169 bAcceptHyphen = false;
170 }
171 else
172 {
173 is.Union(Interval<Char>(token.ch, token.ch));
174 chLastChar = token.ch;
175 bAcceptHyphen = true;
176 }
177 }
178 break;
179 default:
180 {
181 Backward(token);
182 bContinue = false;
183 }
184 break;
185 }
186
187 bFirst = false;
188 }
189
190 if (bOpposite)
191 {
192 IntervalSet<Char> u;
193 u.Union(Interval<Char>(0, -1));
194 is = u.Exclude(is);
195 is.MakeClose(1);
196 }
197
198 StateMachine::NodePtr pCurrent = pNode;
199
200 if (is.IsEmpty())
201 {
202 return pCurrent;
203 }
204
205 pCurrent = NewNode();
206 Set<Interval<Char>> intervals = is.GetIntervals();
207
208 for (auto it = intervals.Begin(); it != intervals.End(); ++it)
209 {
210 StateMachine::EdgePtr pEdge = NewEdge(it->left, it->right);
211 m_spStateMachine->AddEdge(pEdge, pNode, pCurrent);
212 }
213
214 m_spStateMachine->AddNode(pCurrent);
215
216 return pCurrent;
217}
改完以后,我们考虑怎样添加对重复的支持。
状态机
我们举个简单的例子——构造正则表达式“ab?c”的状态机。
首先不考虑最后的“+”,画出“abc”的状态机,这当然很简单:

状态1后,如果遇到字符b,现在直接指向了节点2,匹配了一次b。如何不匹配b呢?没错,从1直接跳到2,增加ε边:

再来考虑“ab+c”,也很明显,添加从2回到1的ε边:

再结合上面两个,就有了“ab*c”:
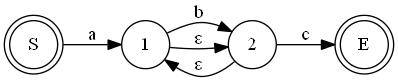
……不对!!!两条ε边死循环了!
可以考虑增加一些辅助节点解开这个死结:

同时把前两个也重画。“ab+c”:

“ab?c”:

可以看出一点规律:
节点2是重复单元的开始,节点3是重复单元的结束,中间如果是括,那么可能有很多节点,这些我们都不管,不影响重复的表达。0次开始的,就从节点1向节点4连一条ε边,跳过整个循环部分;1次开始的,就从节点3向节点4连一条ε边;有任意次重复的,从节点3向节点2连一条ε边。
虽然这里使用了超多的ε边,去掉它们会使状态机显得更加简洁。不过为了规律性更强,这些ε边我们都保留。
最后,说说关于贪婪和非贪婪的处理。这部分在@vczh的《构造正则表达式引擎》里也介绍过。它依赖于实现状态机的图的节点指针存储顺序。我们来看一下状态机的节点结构:
1template <typename NodeData, typename EdgeData>
2struct GraphNode
3{
4 typedef GraphEdge<EdgeData, NodeData> EdgeType;
5
6 NodeData tValue;
7
8 Array<EdgeType *> arrPrevious;
9 Array<EdgeType *> arrNext;
10
11 // ...
12
13};
其中NodeData和EdgeData是在正则表达式这边传递的节点数据和边数据的结构,图这边有序地保存了流出节点的各条边。而我们在匹配的时候,也是按保存的顺序进行遍历的,谁在前,谁就先得到尝试的机会。
所以,对于“ab?c”和“ab*c”,贪婪和非贪婪取决于流出状态1的两条ε边的顺序,如果是先到状态2,便是贪婪,如果先到状态4,便是非贪婪。对于“ab+c”,取决于流出状态3的两条ε边的顺序,如果是先到状态2,便是贪婪,如果先到状态4,便是非贪婪。
代码实现
代码主要修改是ParsePhrase部分,以及增加的ParseRepeater。ParsePhrase目前代码如下:
1StateMachine::NodePtr ParsePhrase(StateMachine::NodePtr pNode)
2{
3 StateMachine::NodePtr pCurrent = ParseWord(pNode);
4
5 if (pCurrent == nullptr)
6 {
7 return nullptr;
8 }
9
10 // TODO: Parse Repeater
11
12 return pCurrent;
13}
开始部分先改成:
1StateMachine::NodePtr ParsePhrase(StateMachine::NodePtr pNode)
2{
3 StateMachine::NodePtr pFrom = NewNode();
4 StateMachine::NodePtr pCurrent = ParseWord(pFrom);
5
6 if (pCurrent == nullptr)
7 {
8 delete pFrom;
9 return nullptr;
10 }
11
12 if (pCurrent == pFrom)
13 {
14 delete pFrom;
15 return pNode;
16 }
17
18 // TODO: Parse Repeater
19 Repeator r = ParseRepeater();
这里先新建了一个pFrom,也就是上面一节状态机图的节点2,作为重复部分的开始,方便之后如果要从状态1(pNode)添加不同顺序的ε边(pNode到pFrom最多只有两条边,仅用来区分贪婪和非贪婪)。解析完Word后,尝试读入Repeater。
Repeater结构定义如下:
1enum RepeatorType
2{
3 RT_None,
4 RT_ZeroOrOne,
5 RT_OnePlus,
6 RT_ZeroPlus
7};
8
9struct Repeator
10{
11 RepeatorType type;
12 bool bGreedy;
13
14 Repeator()
15 : type(RT_None), bGreedy(true)
16 {
17
18 }
19};
RT_None表示没有Repeater,后面三种分别是“?”“+”“*”的效果。然后bGreedy表示是否贪婪模式,默认是,如果读到了额外的“?”,就设为非贪婪模式。ParseRepeater代码如下:
1Repeator ParseRepeater()
2{
3 Repeator r;
4
5 Token token = LookAhead();
6
7 switch (token.type)
8 {
9 case TT_QuestionMark:
10 r.type = RT_ZeroOrOne;
11 break;
12 case TT_Plus:
13 r.type = RT_OnePlus;
14 break;
15 case TT_Star:
16 r.type = RT_ZeroPlus;
17 break;
18 default:
19 Backward(token);
20 break;
21 }
22
23 bool bGreedy = true;
24
25 if (r.type != RT_None)
26 {
27 token = LookAhead();
28
29 if (token.type == TT_QuestionMark)
30 {
31 r.bGreedy = false;
32 }
33 else
34 {
35 Backward(token);
36 }
37 }
38
39 return r;
40}
其中新增的“?”“+”“*”已经添加到单词定义以及词法分析分析函数了。
最后回到ParsePhrase的后半部分:
1 Repeator r = ParseRepeater();
2
3 switch (r.type)
4 {
5 case RT_None:
6 {
7 m_spStateMachine->AddNode(pFrom);
8 StateMachine::EdgePtr pEdge = NewEdge();
9 m_spStateMachine->AddEdge(pEdge, pNode, pFrom);
10 }
11 break;
12 case RT_ZeroOrOne:
13 {
14 m_spStateMachine->AddNode(pFrom);
15 StateMachine::EdgePtr pEdgeNodeToFrom = NewEdge();
16 StateMachine::EdgePtr pEdgeNodeToCurrent = NewEdge();
17
18 if (r.bGreedy)
19 {
20 m_spStateMachine->AddEdge(pEdgeNodeToFrom, pNode, pFrom);
21 m_spStateMachine->AddEdge(pEdgeNodeToCurrent, pNode, pCurrent);
22 }
23 else
24 {
25 m_spStateMachine->AddEdge(pEdgeNodeToCurrent, pNode, pCurrent);
26 m_spStateMachine->AddEdge(pEdgeNodeToFrom, pNode, pFrom);
27 }
28 }
29 break;
30 case RT_OnePlus:
31 {
32 StateMachine::NodePtr pTo = NewNode();
33 m_spStateMachine->AddNode(pFrom);
34 m_spStateMachine->AddNode(pTo);
35
36 StateMachine::EdgePtr pEdgeNodeToFrom = NewEdge();
37 m_spStateMachine->AddEdge(pEdgeNodeToFrom, pNode, pFrom);
38
39 StateMachine::EdgePtr pEdgeCurrentToFrom = NewEdge();
40 StateMachine::EdgePtr pEdgeCurrentToTo = NewEdge();
41
42 if (r.bGreedy)
43 {
44 m_spStateMachine->AddEdge(pEdgeCurrentToFrom, pCurrent, pFrom);
45 m_spStateMachine->AddEdge(pEdgeCurrentToTo, pCurrent, pTo);
46 }
47 else
48 {
49 m_spStateMachine->AddEdge(pEdgeCurrentToTo, pCurrent, pTo);
50 m_spStateMachine->AddEdge(pEdgeCurrentToFrom, pCurrent, pFrom);
51 }
52
53 pCurrent = pTo;
54 }
55 break;
56 case RT_ZeroPlus:
57 {
58 StateMachine::NodePtr pTo = NewNode();
59 m_spStateMachine->AddNode(pFrom);
60 m_spStateMachine->AddNode(pTo);
61
62 StateMachine::EdgePtr pEdgeCurrentToNode = NewEdge();
63 m_spStateMachine->AddEdge(pEdgeCurrentToNode, pCurrent, pNode);
64
65 StateMachine::EdgePtr pEdgeNodeToFrom = NewEdge();
66 StateMachine::EdgePtr pEdgeNodeToTo = NewEdge();
67
68 if (r.bGreedy)
69 {
70 m_spStateMachine->AddEdge(pEdgeNodeToFrom, pNode, pFrom);
71 m_spStateMachine->AddEdge(pEdgeNodeToTo, pNode, pTo);
72 }
73 else
74 {
75 m_spStateMachine->AddEdge(pEdgeNodeToTo, pNode, pTo);
76 m_spStateMachine->AddEdge(pEdgeNodeToFrom, pNode, pFrom);
77 }
78
79 pCurrent = pTo;
80 }
81 break;
82 default:
83 break;
84 }
85
86 return pCurrent;
87}
根据三种不同的Repeater,使用不同的连接方法连状态机节点,bGready影响某两条关键的边的顺序。这里不做过多解释,该解释的都在上一节解释过了。
由于我们引入了贪婪和非贪婪的概念,匹配检验函数Match必然需要支持部分匹配字符串,不然就没法区分两种模式。原先为了方便起见,都是对整个字符串进行匹配的。我们将Match系列函数修改成下面这个样子:
1bool Match(const String &s, int *pnPos = nullptr)
2{
3 return Match(s, 0, m_pBegin, pnPos);
4}
5
6bool Match(const String &s, int i, StateMachine::NodePtr pNode, int *pnPos = nullptr)
7{
8 if (pNode == m_pEnd)
9 {
10 if (pnPos != nullptr)
11 {
12 *pnPos = i;
13 return true;
14 }
15
16 if (i < s.Length())
17 {
18 return false;
19 }
20
21 return true;
22 }
23
24 for (auto it = pNode->arrNext.Begin(); it != pNode->arrNext.End(); ++it)
25 {
26 if (Match(s, i, *it, pnPos))
27 {
28 return true;
29 }
30 }
31
32 return false;
33}
34
35bool Match(const String &s, int i, StateMachine::EdgePtr pEdge, int *pnPos = nullptr)
36{
37 if (!pEdge->tValue.bEpsilon)
38 {
39 if (i >= s.Length())
40 {
41 return false;
42 }
43
44 if (!pEdge->tValue.Match(s[i]))
45 {
46 return false;
47 }
48
49 return Match(s, i + 1, pEdge->pNext, pnPos);
50 }
51 else
52 {
53 return Match(s, i, pEdge->pNext, pnPos);
54 }
55}
新增参数int *pnPos,返回匹配结束后第一个未匹配的字符位置,也就是已匹配的字符数。如果pnPos非空,那么支持部分匹配,返回匹配成功的位置;如果pn为空,还是跟原先一样,进行全字符串匹配。
单元测试
首先跑一下现有的所有case,应该能通过。然后增加几个对pnPos的case:
1RegExp r;
2int nPos = 0;
3
4XL_TEST_ASSERT(r.Parse(L"[0-9]|[0-9][0-9]|[01][0-9][0-9]|2[0-4][0-9]|25[0-5]"));
5XL_TEST_ASSERT(!r.Match(L"256"));
6XL_TEST_ASSERT(!r.Match(L"260"));
7XL_TEST_ASSERT(!r.Match(L"300"));
8XL_TEST_ASSERT(r.Match(L"256", &nPos) && nPos == 2);
9XL_TEST_ASSERT(r.Match(L"260", &nPos) && nPos == 2);
10XL_TEST_ASSERT(r.Match(L"300", &nPos) && nPos == 2);
后三则通不过。原因是0-255的正则表达式在部分匹配的时候有问题。由于正则表达式“[0-9]|[0-9][0-9]|[01][0-9][0-9]|2[0-4][0-9]|25[0-5]”将1位数“[0-9]”放到最前面,使得所有数字都只匹配了第一个就结束了。改正为先写三位数,后写两位数,最后写一位数:“[01][0-9][0-9]|2[0-4][0-9]|25[0-5]|[0-9][0-9]|[0-9]”。所有的“|”子式之间,如果有包含关系,或者有部分重叠,使用的时候就需要考虑顺序,这跟贪婪、非贪婪的道理是一样的。
然后尝试添加针对新功能的case。IPv4地址由于后面重复是3次,本次我们并没有支持计次重复“x{m,n}”,所以没法应用。
写几个土土的case吧:
1
2XL_TEST_CASE()
3{
4 RegExp r;
5 int nPos = 0;
6
7 XL_TEST_ASSERT(!r.Parse(L"?"));
8 XL_TEST_ASSERT(!r.Parse(L"+"));
9 XL_TEST_ASSERT(!r.Parse(L"*"));
10 XL_TEST_ASSERT(!r.Parse(L"??"));
11 XL_TEST_ASSERT(!r.Parse(L"+?"));
12 XL_TEST_ASSERT(!r.Parse(L"*?"));
13
14 XL_TEST_ASSERT(r.Parse(L"a?"));
15 XL_TEST_ASSERT(r.Match(L""));
16 XL_TEST_ASSERT(r.Match(L"a"));
17 XL_TEST_ASSERT(!r.Match(L"aa"));
18 XL_TEST_ASSERT(r.Match(L"", &nPos) && nPos == 0);
19 XL_TEST_ASSERT(r.Match(L"a", &nPos) && nPos == 1);
20 XL_TEST_ASSERT(r.Match(L"aa", &nPos) && nPos == 1);
21
22 XL_TEST_ASSERT(r.Parse(L"a??"));
23 XL_TEST_ASSERT(r.Match(L""));
24 XL_TEST_ASSERT(r.Match(L"a"));
25 XL_TEST_ASSERT(!r.Match(L"aa"));
26 XL_TEST_ASSERT(r.Parse(L"a??"));
27 XL_TEST_ASSERT(r.Match(L"", &nPos) && nPos == 0);
28 XL_TEST_ASSERT(r.Match(L"a", &nPos) && nPos == 0);
29 XL_TEST_ASSERT(r.Match(L"aa", &nPos) && nPos == 0);
30
31 XL_TEST_ASSERT(r.Parse(L"a+"));
32 XL_TEST_ASSERT(!r.Match(L""));
33 XL_TEST_ASSERT(r.Match(L"a"));
34 XL_TEST_ASSERT(r.Match(L"aa"));
35 XL_TEST_ASSERT(r.Match(L"aaa"));
36 XL_TEST_ASSERT(!r.Match(L"", &nPos));
37 XL_TEST_ASSERT(r.Match(L"a", &nPos) && nPos == 1);
38 XL_TEST_ASSERT(r.Match(L"aa", &nPos) && nPos == 2);
39 XL_TEST_ASSERT(r.Match(L"aaa", &nPos) && nPos == 3);
40
41 XL_TEST_ASSERT(r.Parse(L"a+?"));
42 XL_TEST_ASSERT(!r.Match(L""));
43 XL_TEST_ASSERT(r.Match(L"a"));
44 XL_TEST_ASSERT(r.Match(L"aa"));
45 XL_TEST_ASSERT(r.Match(L"aaa"));
46 XL_TEST_ASSERT(!r.Match(L"", &nPos));
47 XL_TEST_ASSERT(r.Match(L"a", &nPos) && nPos == 1);
48 XL_TEST_ASSERT(r.Match(L"aa", &nPos) && nPos == 1);
49 XL_TEST_ASSERT(r.Match(L"aaa", &nPos) && nPos == 1);
50
51 XL_TEST_ASSERT(r.Parse(L"a*"));
52 XL_TEST_ASSERT(r.Match(L""));
53 XL_TEST_ASSERT(r.Match(L"a"));
54 XL_TEST_ASSERT(r.Match(L"aa"));
55 XL_TEST_ASSERT(r.Match(L"aaa"));
56 XL_TEST_ASSERT(r.Match(L"", &nPos) && nPos == 0);
57 XL_TEST_ASSERT(r.Match(L"a", &nPos) && nPos == 1);
58 XL_TEST_ASSERT(r.Match(L"aa", &nPos) && nPos == 2);
59 XL_TEST_ASSERT(r.Match(L"aaa", &nPos) && nPos == 3);
60 XL_TEST_ASSERT(r.Parse(L"a*?"));
61 XL_TEST_ASSERT(r.Match(L""));
62 XL_TEST_ASSERT(r.Match(L"a"));
63 XL_TEST_ASSERT(r.Match(L"aa"));
64 XL_TEST_ASSERT(r.Match(L"aaa"));
65 XL_TEST_ASSERT(r.Match(L"", &nPos) && nPos == 0);
66 XL_TEST_ASSERT(r.Match(L"a", &nPos) && nPos == 0);
67 XL_TEST_ASSERT(r.Match(L"aa", &nPos) && nPos == 0);
68 XL_TEST_ASSERT(r.Match(L"aaa", &nPos) && nPos == 0);
69
70 XL_TEST_ASSERT(r.Parse(L"w1+"));
71 XL_TEST_ASSERT(!r.Match(L""));
72 XL_TEST_ASSERT(!r.Match(L"w"));
73 XL_TEST_ASSERT(r.Match(L"w1"));
74 XL_TEST_ASSERT(r.Match(L"w11"));
75 XL_TEST_ASSERT(r.Match(L"w111"));
76 XL_TEST_ASSERT(r.Match(L"w1111"));
77 XL_TEST_ASSERT(r.Match(L"w11111"));
78 XL_TEST_ASSERT(!r.Match(L"", &nPos));
79 XL_TEST_ASSERT(!r.Match(L"w", &nPos));
80 XL_TEST_ASSERT(r.Match(L"w1", &nPos) && nPos == 2);
81 XL_TEST_ASSERT(r.Match(L"w11", &nPos) && nPos == 3);
82 XL_TEST_ASSERT(r.Match(L"w111", &nPos) && nPos == 4);
83 XL_TEST_ASSERT(r.Match(L"w1111", &nPos) && nPos == 5);
84 XL_TEST_ASSERT(r.Match(L"w11111", &nPos) && nPos == 6);
85
86 XL_TEST_ASSERT(r.Parse(L"w1+?"));
87 XL_TEST_ASSERT(!r.Match(L""));
88 XL_TEST_ASSERT(!r.Match(L"w"));
89 XL_TEST_ASSERT(r.Match(L"w1"));
90 XL_TEST_ASSERT(r.Match(L"w11"));
91 XL_TEST_ASSERT(r.Match(L"w111"));
92 XL_TEST_ASSERT(r.Match(L"w1111"));
93 XL_TEST_ASSERT(r.Match(L"w11111"));
94 XL_TEST_ASSERT(!r.Match(L"", &nPos));
95 XL_TEST_ASSERT(!r.Match(L"w", &nPos));
96 XL_TEST_ASSERT(r.Match(L"w1", &nPos) && nPos == 2);
97 XL_TEST_ASSERT(r.Match(L"w11", &nPos) && nPos == 2);
98 XL_TEST_ASSERT(r.Match(L"w111", &nPos) && nPos == 2);
99 XL_TEST_ASSERT(r.Match(L"w1111", &nPos) && nPos == 2);
100 XL_TEST_ASSERT(r.Match(L"w11111", &nPos) && nPos == 2);
101}
或许可以尝试匹配URL:
1XL_TEST_CASE()
2{
3 RegExp r;
4
5 XL_TEST_ASSERT(r.Parse(L"http://([a-zA-Z0-9\\-]+.)+[a-zA-Z]+/"));
6 XL_TEST_ASSERT(r.Match(L"http://streamlet.org/"));
7 XL_TEST_ASSERT(r.Match(L"http://www.streamlet.org/"));
8 XL_TEST_ASSERT(r.Match(L"http://www.1-2.streamlet.org/"));
9 XL_TEST_ASSERT(r.Match(L"http://www.1-2.3-4.streamlet.org/"));
10 XL_TEST_ASSERT(!r.Match(L"http://org/"));
11 XL_TEST_ASSERT(!r.Match(L"http://streamlet.o-g/"));
12}
小结
这次我们实现了重复,且支持非贪婪模式,使得实用性大大增加了。不过,同样实用的计次重复却没有实现。这是由于以下两方面原因:
第一、计次重复需要复制状态机节点,如“ab{2,5}c”的状态机将是这样的:

如果是“a(…){2,5}c”,中间要复制的玩意儿就多了。目前状态机操作方面还没有支持复制一张子图的功能。
第二,由于“x{m,n}”中的m、n并不仅仅是1个字符,虽然处理上并不成问题,但这超出了开头提出的“每个词法单元都是单个字符”的愿望。单单为了秉承此美好愿望,也不应该支持。此事我们以后会回过头来处理。
通过本篇以及前面两篇,我们得到了一个勉强能用的正则表达式,已实现的语法与市面上的正则表达式是一样的(未实现的当然还是未实现啦)。但是,状态机部分仍然处于原始状态,特别是经过本次的修改,ε边弥漫,极大地影响匹配的效率。下一篇我们将系统了解下ε-NFA、NFA、DFA的概念,然后做一定的优化。
首发:http://www.cppblog.com/Streamlet/archive/2012/06/08/178126.html