解析正则表达式(二)字符集合
2012-06-04 22:19:00
引言
这篇我们要实现的是中括号表达式。
一个中括号里写上任意数目的字符,表示匹配这些字符中的任何一个。比如“[abc]”匹配a或b或c。中括号里除了单个字符,也可以写字符区间,比如“[a-c]”就表示从a到c的所有字符,这里“a到c”是指内码连续的一系列字符,包含首尾的a和c。综合起来说,中括号里面可以放任意个字符或者字符区间,匹配所填字符或字符区间内的任意一个字符。比如“[acd-f]”可以匹配a、c、d、e、f这五个字符。
还有一种否定的形式,在中括号最前面写一个“^”,其余部分不变,这用于匹配除了所描述的字符集合之外的所有字符。也就是取所表述的字符集合的补集的意思,既然有补集,便有全集,全集是正则表达式所支持的普通字符的全体。
不管肯定形式还是否定形式,中括号表达式都表示了一种字符集合。
语法分析
文法介绍
我们用 EBNF 文法描述集合表达式:
"[" [ "^" ] { OrdinaryChar | OrdinaryChar "-" OrdinaryChar } "]"
首尾是中括号,中括号里面开头可能有“^”,接下来是若干个字符或者字符区间。
中括号表达式的优先级很高,比小括号还要高。上一篇我们的整个正则表达式文法是:
Expr -> ExprNoOr { "|" ExprNoOr }
ExprNoOr -> ExprNoGroup { "(" Expr ")" ExprNoGroup }
ExprNoGroup -> { OrdinaryChar }
由于中括号表达式的增加,ExprNoGroup 不再是那么简单了。现在文法要改为:
Expr -> ExprNoOr { "|" ExprNoOr }
ExprNoOr -> ExprNoGroup { "(" Expr ")" ExprNoGroup }
ExprNoGroup -> ExprNoCollection { "[" ExprCollection "]" ExprNoCollection }
ExprCollection -> [ "^" ] { OrdinaryChar | OrdinaryChar "-" OrdinaryChar }
ExprNoCollection -> { OrdinaryChar }
ExprNoCollection 取代了之前的ExprNoGroup,而ExprNoGroup 的结构变得和 ExprNoOr 类似,新增的ExprCollection用于描述中括号之内的文法。
状态机
回顾一下我们之前对状态机的边的数据结构定义:
1struct Edge
2{
3 Edge()
4 : m_bEpsilon(true), m_chBegin(0), m_chEnd(0)
5 {
6
7 }
8
9 Edge(Char ch)
10 : m_bEpsilon(false), m_chBegin(ch), m_chEnd(ch)
11 {
12
13 }
14
15 Edge(Char chBegin, Char chEnd)
16 : m_bEpsilon(false), m_chBegin(chBegin), m_chEnd(chEnd)
17 {
18
19 }
20
21 bool Match(Char ch)
22 {
23 if (m_bEpsilon)
24 {
25 return false;
26 }
27
28 return (ch >= m_chBegin && ch <= m_chEnd);
29 }
30
31 bool bEpsilon;
32 Char chBegin;
33 Char chEnd;
34};
该数据结构可以支持表示一个区间。比如表达式“a[1-358]b”,它的状态机结构为:
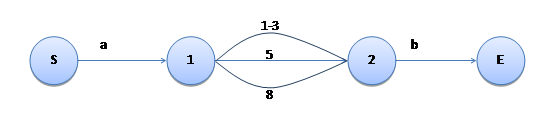
其中 1-3 占用一条边。
在考虑否定的形式,将刚才的表达式修改成“a[^1-358]b”,状态机能保持类似结构吗?是否可以给边增加一个属性,表示“处于否定状态”呢?
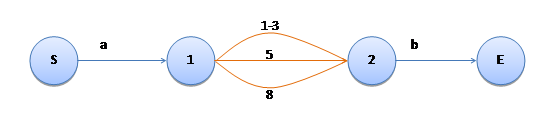
如上图,加入橘黄色的边表示“否定边”,那么,如何进行匹配检验呢?假设到了1号状态后,后续字符是“5”,走第一条边“1-3”,通过!这显然与期望不一致,我们希望“5”被阻挡,因为“[^1-358]”中不包含“5”。原因是,我们之前状态机的同一节点的后续各条边之间是逻辑或关系,只要有一条通过即可,而引入“否定边”后,我们需要对这些边做逻辑与操作,只有每条边都通过才行。这样,可以考虑将并联改成串联:
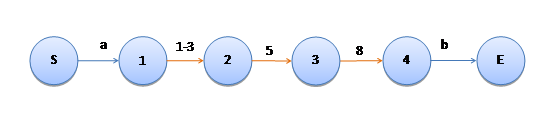
并联改串联是刚刚写到这里的时候想到的。下午在写代码的时候想到的是另一个方案——对集合求补集。“[^1-358]”等价于“[-046-79-#]”,其中我暂时用“”表示第一个字符(U+0000),用“#”表示最后一个字符(U+FFFF)。这样,状态机的形式为:
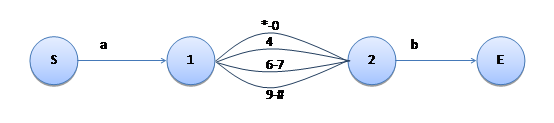
(现在觉得串联的形式更美了。本文先按补集方案做,串联方案因为匹配的时候只有第一条边可以消耗字符,后续的边不能消耗字符了,不是很方便处理,再想想。)
集合运算
集合运算一开始是由于需要求补集才引入的。如果不求补集,可以不用,无非重复的边多一些。如表达式“[1-54-6]”,那么可能需要一条“1-5”的边,一条“4-6”的边,引入集合运算后,可以合为一条“1-6”边。
对于否定形式的“[^1-54-6]”,则必须进行集合运算了:先将两个区间并为“1-6”,再求补,得到“*-0”和“7-#”。也可以先对每个区间求补,最后求交集。
首先是区间的概念。代码见: http://xllib.codeplex.com/SourceControl/changeset/view/16818#270866
相关函数简要介绍如下:
1template <typename T>
2struct Interval
3{
4 T left; // 左端点
5 T right; // 右端点
6 bool bIncludeLeft; // 是否包含左端点
7 bool bIncludeRight; // 是否包含右端点
8
9 // 一系列构造函数等
10 Interval();
11 Interval(T left, T right, bool bIncludeLeft = true, bool bIncludeRight = true);
12 Interval(const Interval &that);
13 ~Interval();
14
15 // 一系列运算符
16 Interval &operator = (const Interval &that);
17 bool operator == (const Interval &that) const;
18 bool operator != (const Interval &that) const;
19 bool operator < (const Interval &that) const;
20 bool operator > (const Interval &that) const;
21 bool operator <= (const Interval &that) const;
22 bool operator >= (const Interval &that) const;
23
24 // 是否为空集
25 bool IsEmpty() const;
26 //是否包含某元素
27 bool Contains(const T &v) const;
28 // 是否包含某区间(子集)
29 bool Contains(const Interval &that) const;
30 // 是否被某区间包含(超集)
31 bool ContainedBy(const Interval &that) const;
32 // 求交集
33 Interval Intersection(const Interval &that) const;
34 // 是否相交
35 bool HasIntersectionWith(const Interval &that) const;
36 // 是否相连
37 bool Touched(const Interval &that) const;
38 // 求相连两集合的并集
39 Interval UnionTouched(const Interval &that) const;
40 // 求并集(不管是否相连)
41 Set<Interval> Union(const Interval &that) const;
42 // 去除一个区间(差集)
43 Set<Interval> Exclude(const Interval &that) const;
44 // 变成闭区间
45 Interval CloseInterval(const T step);
46};
其中,两个 bool 变量表示两个端点的开闭。
大小比较,空集永远等于空集,两集合的大小先看左端点再看右端点,左端点相同时闭的比开的小,右端点相同时开的比闭的小。
“相连”的概念是指,有交集,或者其中一个的左端点等于另一个的右端点,两点一开一闭。UnionTouched,是指两个区间可以并成一个区间的时候,求并了之后的结果,如果不能并为一个区间,那么返回自己。Union 就是普遍意义的区间并,可能会并成2个间断的区间。
Exclude 是差集的概念,一个区间对另一个区间求差集,可能会断裂成2个区间。补集运算就不再搞一个了,一个集合对全集求补,相当于全集对它求差。
最后一个,表示把开区间变成闭区间,其中带有一点离散化的概念,需要知道离散化的步长(粒度)。如果左端点是开的,那么CloseInterval操作就是把左端点加上step,并改为闭的;右端点也类似,只是要减去step而不是加上。
从上面几个运算来看,求交和求“相连并”这两个运算对于区间是封闭的,求并、求差都不封闭。
有了区间,我们再鼓捣出一个区间集: http://xllib.codeplex.com/SourceControl/changeset/view/16818#270871
1template <typename T>
2class IntervalSet
3{
4 typedef Interval<T> IntervalType;
5 Set<IntervalType> m_setIntervals; // 保存区间集
6
7 // 构造和析构
8 IntervalSet()
9 IntervalSet(const IntervalSet &that)
10 ~IntervalSet()
11
12 // 一系列运算符
13 IntervalSet &operator = (const IntervalSet &that)
14 bool operator == (IntervalSet &that) const
15 bool operator != (IntervalSet &that) const
16
17 // 取出区间集里的区间
18 Set<IntervalType> GetIntervals()
19
20 // 是否为空集
21 bool IsEmpty() const
22
23 // 对单个区间作交、并、差
24 void Intersect(const IntervalType &interval)
25 void Union(const IntervalType &interval)
26 void Exclude(const IntervalType &interval)
27
28 // 对区间集求交、并、差
29 IntervalSet Intersection(const IntervalSet &that) const
30 IntervalSet Union(const IntervalSet &that) const
31 IntervalSet Exclude(const IntervalSet &that) const
32
33 // 变成闭区间集
34 void MakeClose(const T &step)
35};
相关概念类似,不再做过多解释了。
到了这里,我们可以表达任意集合了,区间、单点(左右端点相同的闭区间),以及它们的任意并,都可以表达了。
下面,我们走出集合运算,把目光重新聚集到正则表达式解析上来。
代码实现
由于文法改变,我们需要修改Token定义和LookAhead,以便增加新的语法元素“[”“]”“^”“-”,然后修改 ExprNoGroup,并增加ExprCollection、ExprNoCollection。
Token和LookAhead的变化很简单:
1enum TokenType
2{
3 TT_Eof,
4 TT_VerticalBar, // |
5 TT_OpenParen, // (
6 TT_CloseParen, // )
7 TT_OpenBracket, // [
8 TT_CloseBracket, // ]
9 TT_Hyphen, // -
10 TT_Caret, // ^
11 TT_OrdinaryChar
12};
13
14Token LookAhead()
15{
16 if (m_nCurrentPosition >= m_strRegExp.Length())
17 {
18 return Token(TT_Eof, 0, 0);
19 }
20
21 Char ch = m_strRegExp[m_nCurrentPosition++];
22 TokenType type = TT_OrdinaryChar;
23
24 if (ch == L'\\')
25 {
26 if (m_nCurrentPosition < m_strRegExp.Length())
27 {
28 return Token(TT_OrdinaryChar, m_strRegExp[m_nCurrentPosition++], 2);
29 }
30 }
31
32 switch (ch)
33 {
34 case L'|':
35 type = TT_VerticalBar;
36 break;
37 case L'(':
38 type = TT_OpenParen;
39 break;
40 case L')':
41 type = TT_CloseParen;
42 break;
43 case L'[':
44 type = TT_OpenBracket;
45 break;
46 case L']':
47 type = TT_CloseBracket;
48 break;
49 case L'-':
50 type = TT_Hyphen;
51 break;
52 case L'^':
53 type = TT_Caret;
54 break;
55 default:
56 break;
57 }
58
59 return Token(type, ch);
60}
上面,各Token之间是按照优先级从低到高排列的。
因为现在ExprNoCollection承担了原先ExprNoGroup的作用——接受普通字符,因此只要抄原先ExprNoGroup的代码即可:
1StateMachine::NodePtr ParseExprNoCollection(StateMachine::NodePtr pNode)
2{
3 StateMachine::NodePtr pCurrent = pNode;
4
5 while (true)
6 {
7 Token token = LookAhead();
8
9 if (token.type != TT_OrdinaryChar)
10 {
11 Backward(token);
12 return pCurrent;
13 }
14
15 pCurrent = AddNormalNode(pCurrent, token.ch);
16
17 if (pCurrent == nullptr)
18 {
19 return nullptr;
20 }
21 }
22
23 return nullptr;
24}
接下来是ExprNoGroup:
1StateMachine::NodePtr ParseExprNoGroup(StateMachine::NodePtr pNode)
2{
3 StateMachine::NodePtr pCurrent = pNode;
4
5 while (true)
6 {
7 pCurrent = ParseExprNoCollection(pCurrent);
8
9 if (pCurrent == nullptr)
10 {
11 return nullptr;
12 }
13
14 Token token = LookAhead();
15
16 if (token.type != TT_OpenBracket)
17 {
18 Backward(token);
19 return pCurrent;
20 }
21
22 pCurrent = ParseExprCollection(pCurrent);
23
24 if (pCurrent == nullptr)
25 {
26 return nullptr;
27 }
28
29 token = LookAhead();
30
31 if (token.type != TT_CloseBracket)
32 {
33 return nullptr;
34 }
35 }
36
37 return nullptr;
38}
对照文法
ExprNoGroup -> ExprNoCollection { "[" ExprCollection "]" ExprNoCollection }
我们可以发现,它和ExprNoOr写法很像。当然像了,它俩文法就很像,所以实现相像是必然的。
最后我们来看 ExprCollection:
ExprCollection -> [ "^" ] { OrdinaryChar | OrdinaryChar "-" OrdinaryChar }
我先贴一半的代码:
1StateMachine::NodePtr ParseExprCollection(StateMachine::NodePtr pNode)
2{
3 bool bFirst = true;
4 bool bInHyphen = false;
5 bool bAcceptHyphen = false;
6 Char chLastChar = 0;
7
8 bool bOpposite = false;
9 IntervalSet<Char> is;
10
11 bool bContinue = true;
12
13 while (bContinue)
14 {
15 Token token = LookAhead();
16
17 switch (token.type)
18 {
19 case TT_Caret:
20 {
21 if (!bFirst)
22 {
23 return nullptr;
24 }
25 else
26 {
27 bOpposite = true;
28 }
29 }
30 break;
31 case TT_Hyphen:
32 {
33 if (bInHyphen || !bAcceptHyphen)
34 {
35 return nullptr;
36 }
37 else
38 {
39 bInHyphen = true;
40 }
41 }
42 break;
43 case TT_OrdinaryChar:
44 {
45 if (bInHyphen)
46 {
47 is.Union(Interval<Char>(chLastChar, token.ch));
48 bInHyphen = false;
49 bAcceptHyphen = false;
50 }
51 else
52 {
53 is.Union(Interval<Char>(token.ch, token.ch));
54 chLastChar = token.ch;
55 bAcceptHyphen = true;
56 }
57 }
58 break;
59 default:
60 {
61 Backward(token);
62 bContinue = false;
63 }
64 break;
65 }
66
67 bFirst = false;
68 }
这是一个大的循环,同时处理“^”“-”和普通字符。其中“^”必须在第一个字符处出现,否则视为不合法。“-”必须在bInHyphen为false且bAcceptHyphen为true的时候出现,否则也视为不合法。
遇到第一个“^”,将bOpposite置为true,表示整个中括号表达式是否定的。遇到“-”,将bInHyphen设上,待下个字符到来时,与前一个字符共同组合成区间。
上面这个大循环的结果是区间集is以及标识bOpposite。接下来是使用得到的区间集进行必要的运算,并生成状态机:
1 if (bOpposite)
2 {
3 IntervalSet<Char> u;
4 u.Union(Interval<Char>(0, -1));
5 is = u.Exclude(is);
6 is.MakeClose(1);
7 }
8
9 StateMachine::NodePtr pCurrent = pNode;
10
11 if (is.IsEmpty())
12 {
13 return pCurrent;
14 }
15
16 pCurrent = NewNode();
17 Set<Interval<Char>> intervals = is.GetIntervals();
18
19 for (auto it = intervals.Begin(); it != intervals.End(); ++it)
20 {
21 StateMachine::EdgePtr pEdge = NewEdge(it->left, it->right);
22 m_spStateMachine->AddEdge(pEdge, pNode, pCurrent);
23 }
24
25 m_spStateMachine->AddNode(pCurrent);
26
27 return pCurrent;
28}
首先,如果是否定形式的,对整个区间集求一个补,然后搞成闭区间。肯定形式略过这一步。不管肯定形式还是否定形式,如果最后是空集,我现在处理为直接返回当前节点。
如果得到非空的区间集,对其中每个区间生成一条边,连到新节点,就可以了。代码到这里为止。
单元测试
跟上一篇一样,弄点常规测试用例:
1XL_TEST_CASE()
2{
3 RegExp r;
4 XL_TEST_ASSERT(r.Parse(L"[]"));
5 XL_TEST_ASSERT(r.Parse(L"[^]"));
6 XL_TEST_ASSERT(!r.Parse(L"[(]"));
7 XL_TEST_ASSERT(!r.Parse(L"[|]"));
8
9 XL_TEST_ASSERT(r.Parse(L"[1-3a]"));
10 XL_TEST_ASSERT(r.Match(L"1"));
11 XL_TEST_ASSERT(r.Match(L"2"));
12 XL_TEST_ASSERT(r.Match(L"3"));
13 XL_TEST_ASSERT(r.Match(L"a"));
14 XL_TEST_ASSERT(!r.Match(L"0"));
15 XL_TEST_ASSERT(!r.Match(L"4"));
16 XL_TEST_ASSERT(!r.Match(L"b"));
17
18 XL_TEST_ASSERT(r.Parse(L"[^1-3a]"));
19 XL_TEST_ASSERT(!r.Match(L"1"));
20 XL_TEST_ASSERT(!r.Match(L"2"));
21 XL_TEST_ASSERT(!r.Match(L"3"));
22 XL_TEST_ASSERT(!r.Match(L"a"));
23 XL_TEST_ASSERT(r.Match(L"0"));
24 XL_TEST_ASSERT(r.Match(L"4"));
25 XL_TEST_ASSERT(r.Match(L"b"));
26}
嗯,再回顾一下上一篇我们写的匹配0到255的正则表达式:
- 一位数:(0|1|2|3|4|5|6|7|8|9)
- 两位数:(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)
- 三位数:
- 0到199:(0|1)(0|1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)
- 200到249:2(0|1|2|3|4)(0|1|2|3|4|5|6|7|8|9)
- 250到255:25(0|1|2|3|4|5)
我们现在可以来简化一下了:
- 一位数:[0-9]
- 两位数:[0-9][0-9]
- 三位数:
- 0到199:[01][0-9][0-9]
- 200到249:2[0-4][0-9]
- 250到255:25[0-5]
合起来就是“[0-9]|[0-9][0-9]|[01][0-9][0-9]|2[0-4][0-9]|25[0-5]”,比上一篇短多了。使用和之前同样的测试用例进行测试:
1XL_TEST_CASE()
2{
3 RegExp r;
4
5 XL_TEST_ASSERT(r.Parse(L"[0-9]|[0-9][0-9]|[01][0-9][0-9]|2[0-4][0-9]|25[0-5]"));
6 XL_TEST_ASSERT(r.Match(L"0"));
7 XL_TEST_ASSERT(r.Match(L"1"));
8 XL_TEST_ASSERT(r.Match(L"2"));
9 XL_TEST_ASSERT(r.Match(L"3"));
10 XL_TEST_ASSERT(r.Match(L"4"));
11 XL_TEST_ASSERT(r.Match(L"5"));
12 XL_TEST_ASSERT(r.Match(L"6"));
13 XL_TEST_ASSERT(r.Match(L"7"));
14 XL_TEST_ASSERT(r.Match(L"8"));
15 XL_TEST_ASSERT(r.Match(L"9"));
16 XL_TEST_ASSERT(r.Match(L"10"));
17 XL_TEST_ASSERT(r.Match(L"20"));
18 XL_TEST_ASSERT(r.Match(L"30"));
19 XL_TEST_ASSERT(r.Match(L"40"));
20 XL_TEST_ASSERT(r.Match(L"50"));
21 XL_TEST_ASSERT(r.Match(L"60"));
22 XL_TEST_ASSERT(r.Match(L"70"));
23 XL_TEST_ASSERT(r.Match(L"80"));
24 XL_TEST_ASSERT(r.Match(L"90"));
25 XL_TEST_ASSERT(r.Match(L"100"));
26 XL_TEST_ASSERT(r.Match(L"199"));
27 XL_TEST_ASSERT(r.Match(L"200"));
28 XL_TEST_ASSERT(r.Match(L"249"));
29 XL_TEST_ASSERT(r.Match(L"250"));
30 XL_TEST_ASSERT(r.Match(L"251"));
31 XL_TEST_ASSERT(r.Match(L"252"));
32 XL_TEST_ASSERT(r.Match(L"253"));
33 XL_TEST_ASSERT(r.Match(L"254"));
34 XL_TEST_ASSERT(r.Match(L"255"));
35 XL_TEST_ASSERT(!r.Match(L"256"));
36 XL_TEST_ASSERT(!r.Match(L"260"));
37 XL_TEST_ASSERT(!r.Match(L"300"));
38}
同样,画一下状态机。这是使用 Graphviz 来画(感谢 yugi.fanxes 推荐),省去不少力气。Dot源代码如下:
digraph
{
rankdir=LR;
node [shape=circle];
0 [shape=doublecircle];
1 [shape=doublecircle];
0->1 [label="0-9"];
0->2->3 [label="0-9"];
3->1 [label=ε];
0->4 [label="0-1"];
4->5->6 [label="0-9"];
6->1 [label=ε];
0->7 [label=2];
7->8 [label="0-4"]
8->9 [label="0-9"];
9->1 [label=ε];
0->10 [label=2];
10->11 [label=5];
11->12 [label="0-6"]
12->1 [label=ε];
}
状态机:

由于边数据结构支持表示字符区间,这次我们使用了这个特性,使得状态机简化了很多。
相应的,IPv4地址的表示也可以变得更短:
1XL_TEST_CASE()
2{
3 RegExp r;
4
5 // IPv4 address
6 XL_TEST_ASSERT(r.Parse(L"("
7 L"[0-9]|[0-9][0-9]|[01][0-9][0-9]|2[0-4][0-9]|25[0-5]"
8 L").("
9 L"[0-9]|[0-9][0-9]|[01][0-9][0-9]|2[0-4][0-9]|25[0-5]"
10 L").("
11 L"[0-9]|[0-9][0-9]|[01][0-9][0-9]|2[0-4][0-9]|25[0-5]"
12 L").("
13 L"[0-9]|[0-9][0-9]|[01][0-9][0-9]|2[0-4][0-9]|25[0-5]"
14 L")"));
15 XL_TEST_ASSERT(r.Match(L"192.168.1.1"));
16 XL_TEST_ASSERT(r.Match(L"0.0.0.0"));
17 XL_TEST_ASSERT(r.Match(L"255.255.255.255"));
18 XL_TEST_ASSERT(!r.Match(L"0.0.0.256"));
19}
小结
本文在上一篇的基础上,增加了“[”“]”“^”“-”四个符号的处理,支持了字符集合的表达。字符集合的表达还是能带来很大方便的,到目前为止,我们的“正则表达式”功能已经有有点雏形了,可以用来做一些简单的事情了。
本文中涉及的实现代码在: http://xllib.codeplex.com/SourceControl/changeset/view/16849#270275
下一篇,将实现“重复”的处理,即“?”“+”“*”这三个符号的解析。
首发:http://www.cppblog.com/Streamlet/archive/2012/06/04/177532.html